| Towards a Unified Compositional Model for Visual Pattern Modeling |
| |
| Wei Tang, Pei Yu, Jiahuan Zhou, and Ying Wu |
| |
| EECS Department, Northwestern Unversity, USA |
| |
| Abstract |
Compositional models represent visual patterns as hierarchies of meaningful and reusable parts. They are attractive to vision modeling due to their ability to decompose complex patterns into simpler ones and resolve the low-level ambiguities in high-level image interpretations. However, current compositional models separate structure and part discovery from parameter estimation, which generally leads to suboptimal learning and fitting of the model. Moreover, the commonly adopted latent structural learning is not
scalable for deep architectures. To address these difficult issues for compositional models, this paper quests for a unified framework for compositional pattern modeling, inference and learning. Represented by And-Or graphs (AOGs), it jointly models the compositional structure, parts, features, and composition/sub-configuration relationships. We show that the inference algorithm of the proposed framework is equivalent to a feed-forward network. Thus, all the parameters can be learned efficiently via the highly-scalable back-propagation (BP) in an end-to-end fashion.
We validate the model via the task of handwritten digit recognition. By visualizing the processes of bottom-up composition and top-down parsing, we show that our model is fully interpretable, being able to learn the hierarchical compositions from visual primitives to visual patterns at increasingly higher levels. We apply this new compositional model to natural scene character recognition and generic object detection. Experimental results have demonstrated its effectiveness.
|
| |
| Overview |
| |
 |
|
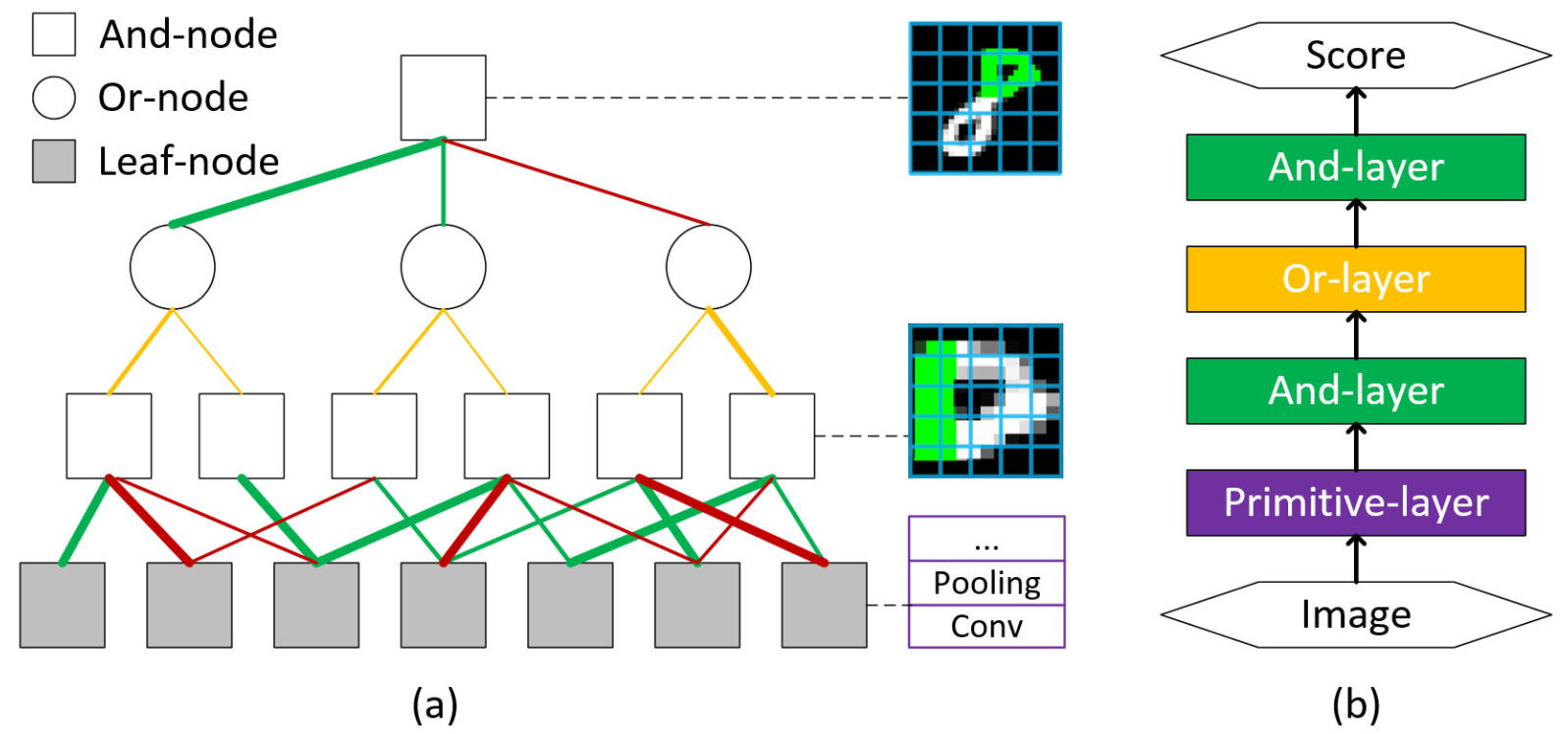
| (a) Our approach, based on AOGs, models the compositional structure, parts, features and composition/sub-configuration relationships in a unified framework. The And-node characterizes subpart-part compositions in a local window and involves longer-range contexts via multiscale modeling. Or-nodes point to switchable sub-configurations with different biases (indicated by the line widths). Leaf-nodes model primitives, the lowest-level parts, via CNNs. The structure is discovered via learning the connection polarities and strengths between And-nodes and their children, respectively indicated by the line colors and widths. (b) The inference is equivalent to a feed-forward network. All the parameters in (a) can be learned end-to-end via BP. |
| |
Resources
|
| Poster: compnet_poster.pptx |
| Source codes and demos: compnet_code.zip |
| Please contact Wei Tang (weitang2015 AT u.northwestern.edu) for any questions concerning this project. |
| |
| References |
[1] W. Tang, P. Yu, J. Zhou, and Y. Wu. Towards a Unified Compositional Model for Visual Pattern Modeling. In ICCV, 2017.
|
| [2] S. Geman, D. F. Potter, and Z. Chi. Composition systems. Quarterly of Applied Mathematics, 2002. |
| [3] S.-C. Zhu and D. Mumford. A stochastic grammar of images. Now Publishers Inc, 2007. |
[4] L. L. Zhu, Y. Chen, and A. Yuille. Recursive compositional models for vision: Description and review of recent work. Journal of Mathematical Imaging and Vision, 2011.
|
| |